

LocalAI是一个开源的、免费的OpenAI替代品,它允许用户在本地环境中运行大型语言模型(LLMs)、生成图像和音频等。它支持多种模型系列,包括ggml、gguf、GPTQ、onnx和TensorFlow兼容的模型,如llama、llama2、rwkv、whisper、vicuna、koala、cerebras、falcon、dolly、starcoder等。
1️⃣ LocalAI的功能特性
- 文本生成:使用GPTs进行文本生成,例如llama.cpp,gpt4all.cpp等。
- 语音转文本:可以将音频转换为文本,使用whisper.cpp进行音频转录。
- 文本转语音:可以将文本转换为语音。
- 图像生成:使用稳定扩散进行图像生成。
- 新的OpenAI功能:提供了一些新的OpenAI功能。
- 向量数据库嵌入:可以为向量数据库生成嵌入。
- 约束语法:提供了约束语法功能。
- 视觉API:提供了直接从Huggingface下载模型的视觉API。
2️⃣ LocalAI的部署方法
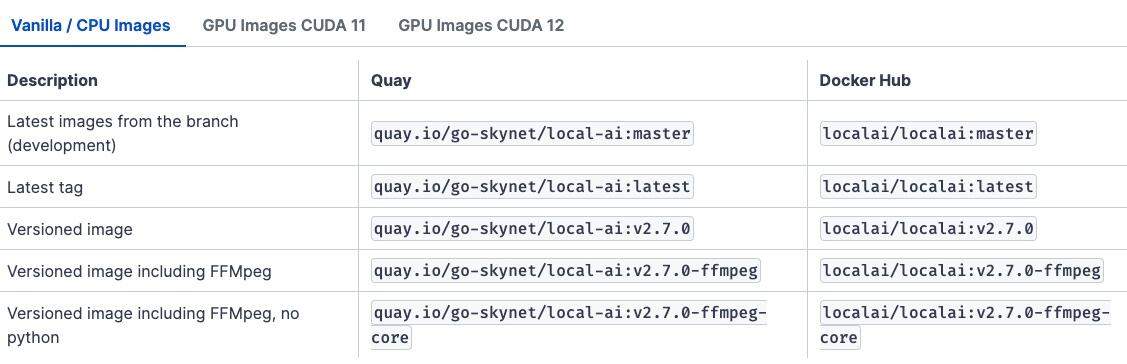
LocalAI提供了容器镜像和二进制文件,兼容各种容器引擎,如Docker、Podman和Kubernetes。容器镜像发布在quay.io和Docker Hub上。二进制文件可以从GitHub下载。
Docker镜像
LocalAI提供了多种镜像来支持不同的环境。这些镜像可以在quay.io和Docker Hub上找到。
可用的镜像类型:
- 以-core结尾的图像是较小的图像,没有预下载Python依赖项。如果你计划使用llama.cpp、stablediffusion-ncn、tinydream或rwkv后端,请使用这些镜像。如果你不确定要使用哪个,请不要使用这些镜像。
- 由于许可证问题,FFMpeg未包含在默认图像中。如果你需要FFMpeg,请使用以-ffmpeg结尾的图像。请注意,在使用音频到文本LocalAI功能时需要ffmpeg。
- 如果使用旧的和过时的CPU而没有GPU,则可能需要将REBUILD设置为true作为环境变量,并禁用你的CPU不支持的标志选项,但是请注意,推理将执行得很差并且很慢。另请参阅标志集兼容性。
- 对于Nvidia显卡的GPU加速支持,请使用Nvidia/CUDA镜像。如果你没有GPU,请使用CPU镜像。如果你有AMD或Mac Silicon,则需要自行使用源码构建镜像。
启动Docker
有关详细的分步介绍,可以参考官方《入门指南》。对于急于求成的人,以下是使用docker启动带有phi-2的LocalAI实例的简单命令(笔者是在自己的NAS运行的):
# 创建models目录
mkdir models
#将你需要的模型拷贝到models目录
cp your-model.gguf models/
# 启动Docker容器
docker run -p 8080:8080 \
-v $PWD/models:/models \
-ti --rm quay.io/go-skynet/local-ai:latest \
--models-path /models --context-size 700 --threads 4
3️⃣ LocalAI的简单使用
等到LocalAI启动后,就可以通过发送HTTP请求到此地址来与LocalAI进行交互。例如,可以使用以下命令发送一个文本生成请求:
curl http://localhost:8080/v1/completions
-H "Content-Type: application/json"
-d
'{
"model": "your-model.gguf",
"prompt": "A long time ago in a galaxy far, far away",
"temperature": 0.7
}'
这将返回一个包含生成文本的JSON对象。更多关于如何使用LocalAI的信息,可以参考官方文档和示例代码。
当然,我们也可以将LocalAI接入到one-api平台,由one-api来统一管理模型,然后再通过FastGPT来调用大模型,完美替代OpenAI,真香!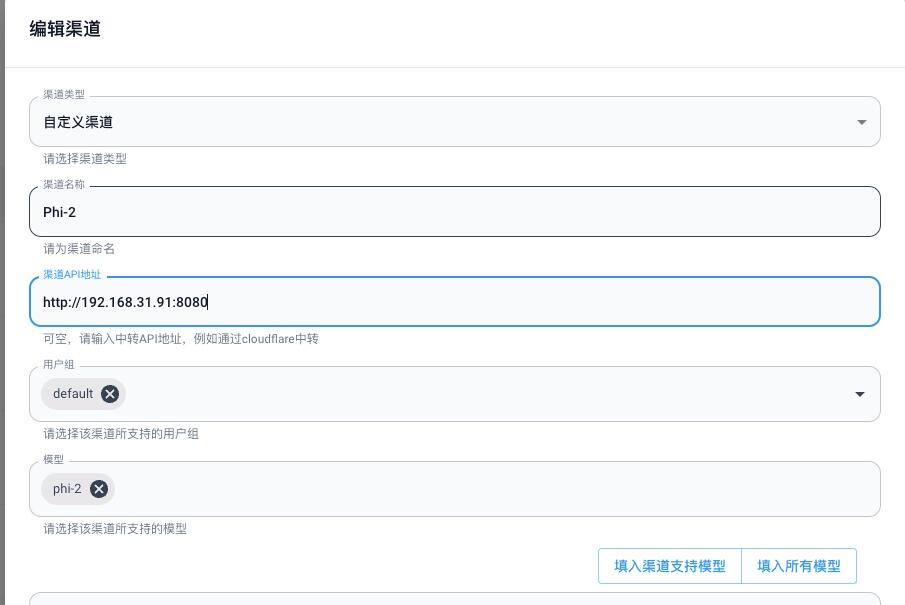
原创不易,如果觉得此文对你有帮助,不妨点赞+收藏+关注,你的鼓励是我持续创作的动力!

原创文章,作者:诺多,如若转载,请注明出处:https://www.huluohu.com/posts/963/
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 




评论列表(2条)
这个应该比较慢吧,而且群晖的感觉带不动
@ink:慢不慢还得看装备哈哈哈🤣